Pure Python LLM inference.
Background
After having briefly played around with LLM inference engines for a while1, I wanted to do a deep dive into the implementation of LLM inference engines for my own understanding. What I found were two great minimal implementations of the most popular contemporary inference engines: nano-vllm and mini-sglang. While nano-vllm was great for understanding the bare essentials, its lack of support for online serving made me more interested in diving deeper into mini-sglang. The use of C++ for radix cache key comparison, plus CUDA and Triton kernels for ops such as KV-cache indexing, stood out to me because they didn't seem obviously too slow if written in Python/Torch. After reading the QuACK blog post on how to get memory-bound kernels to speed-of-light using CuTe-DSL, I figured it'd be a fun exercise rewriting all C++ and CUDA in Numba, CuTe-DSL, CuTile, and NCCL4Py.
Btw, all the code I reference below lives in andrewhinh/llm-engine.
The Code
We'll focus on llmeng/kernel_old and llmeng/kernel_new/ since they contain the juiciest bits. These are all the Python interfaces and the custom kernels they require, in order of complexity:
fast_compare_key: C++ function to compare two contiguous 1D CPU integer tensors and return the first mismatch position, i.e., the matched prefix length. Used by the radix-tree prefix cache to determine how many cached KV pages can be reused.store_cache: CUDA kernel to write per-token k and v rows into the KV cache at locations given by indices.indexing: CUDA kernel for faster lookup, used in the tied embeddings in the LM head.fused_moe_kernel_triton/moe_sum_reduce_triton: Triton kernels for fused MoE routing. The first block matmuls tokens by their corresponding expert matrices, while the second sums the top-k expert outputs back into one hidden-state vector per token.init_pynccl/PyNCCLCommunicator: Python and CUDA wrappers for the NCCL communicator to enable tensor parallelism.
For each kernel, we'll go through the mini-sglang implementation, understand what it does, and then explain how our implementation works and how it compares.
fast_compare_key
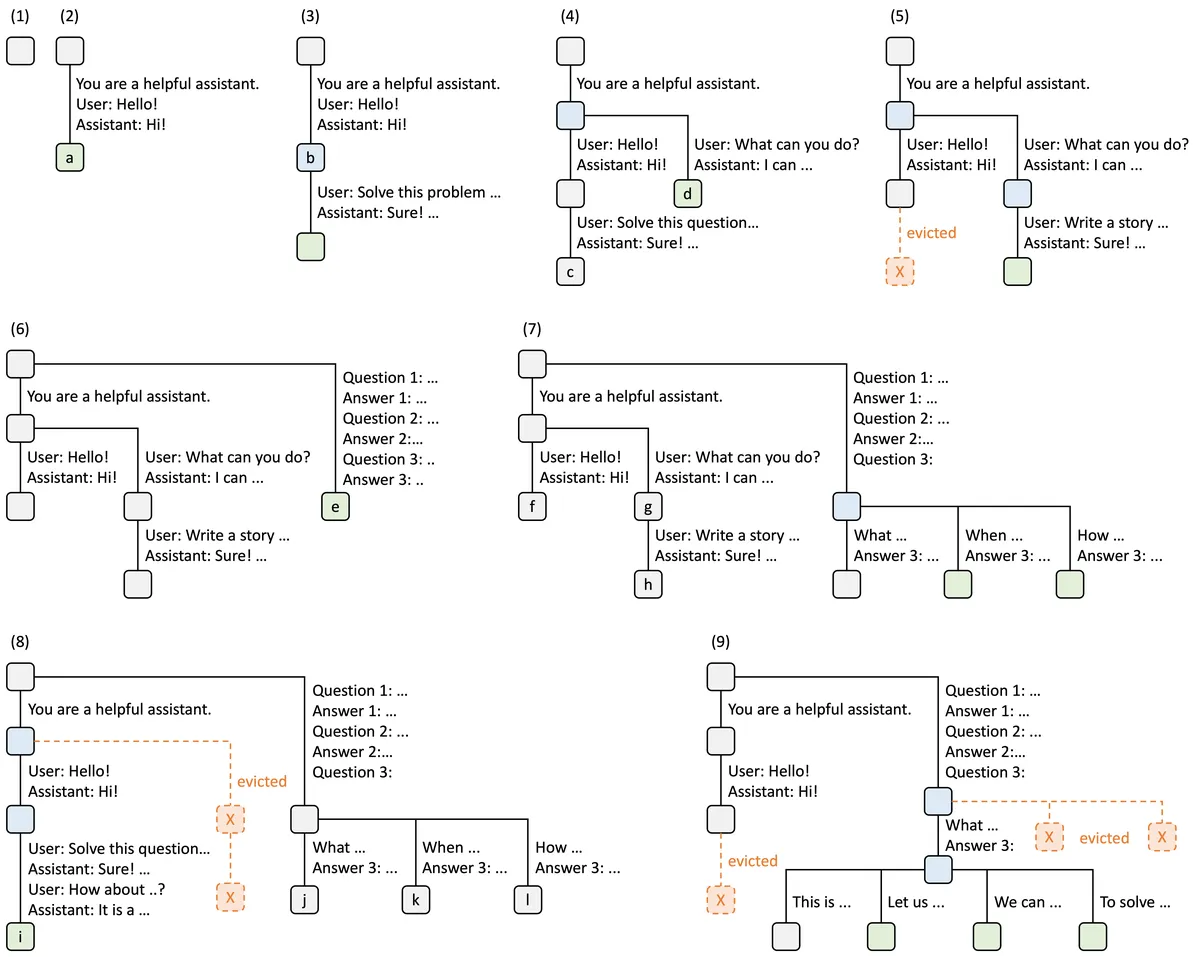
Given a cached token prefix in RadixTreeNode._key and a new input_ids tensor, this kernel finds the first mismatch. The kernel is used in RadixPrefixCache._tree_walk() to determine when to split nodes. As we'll see, this kernel is memory-bound, so the goal is to minimize overhead.
mini-sglang
// llmeng/kernel_old/csrc/src/radix.cpp
auto _is_1d_cpu_int_tensor(const tvm::ffi::TensorView tensor) -> bool {
return tensor.ndim() == 1 && tensor.is_contiguous() &&
tensor.device().device_type == kDLCPU &&
(tensor.dtype().code == kDLInt) &&
(tensor.dtype().bits == 32 || tensor.dtype().bits == 64);
}
auto fast_compare_key(const tvm::ffi::TensorView a,
const tvm::ffi::TensorView b) -> size_t {
host::RuntimeCheck(_is_1d_cpu_int_tensor(a) && _is_1d_cpu_int_tensor(b),
"Both tensors must be 1D CPU int tensors.");
host::RuntimeCheck(a.dtype() == b.dtype());
const auto a_ptr = a.data_ptr();
const auto b_ptr = b.data_ptr();
const auto common_len = std::min(a.size(0), b.size(0));
if (a.dtype().bits == 64) {
const auto a_ptr_64 = static_cast<const int64_t *>(a_ptr);
const auto b_ptr_64 = static_cast<const int64_t *>(b_ptr);
const auto diff_pos =
std::mismatch(a_ptr_64, a_ptr_64 + common_len, b_ptr_64);
return static_cast<size_t>(diff_pos.first - a_ptr_64);
} else {
const auto a_ptr_32 = static_cast<const int32_t *>(a_ptr);
const auto b_ptr_32 = static_cast<const int32_t *>(b_ptr);
const auto diff_pos =
std::mismatch(a_ptr_32, a_ptr_32 + common_len, b_ptr_32);
return static_cast<size_t>(diff_pos.first - a_ptr_32);
}
}
After some basic checks (i.e., both input tensors are 1D, contiguous, and CPU arrays), we branch by 32-bit or 64-bit to avoid per-element branching and compare each element using std::mismatch, relying mostly on the compiler to vectorize the loop. Fairly simple.
llm-engine
# llmeng/kernel_new/radix.py
@numba.njit(cache=True, boundscheck=False)
def _fast_compare_i32(x: np.ndarray, y: np.ndarray) -> int:
n = min(x.shape[0], y.shape[0])
n_pair = (n // 2) * 2
if n_pair > 0:
xv = x[:n_pair].view(np.int64)
yv = y[:n_pair].view(np.int64)
for j in range(xv.shape[0]):
if xv[j] != yv[j]:
i0 = j * 2
if x[i0] != y[i0]:
return i0
return i0 + 1
if n_pair < n and x[n_pair] != y[n_pair]:
return n_pair
return n
@numba.njit(cache=True, boundscheck=False)
def _fast_compare_i64(x: np.ndarray, y: np.ndarray) -> int:
n = min(x.shape[0], y.shape[0])
for idx in range(n):
if x[idx] != y[idx]:
return idx
return n
def _check_tensor(name: str, tensor: torch.Tensor) -> None:
if tensor.ndim != 1:
raise RuntimeError(f"{name} must be 1D")
if not tensor.is_contiguous():
raise RuntimeError(f"{name} must be contiguous")
if tensor.device.type != "cpu":
raise RuntimeError(f"{name} must be on CPU")
if tensor.dtype not in (torch.int32, torch.int64):
raise RuntimeError(f"{name} must have dtype int32 or int64")
def fast_compare_key(x: torch.Tensor, y: torch.Tensor) -> int:
_check_tensor("x", x)
_check_tensor("y", y)
if x.dtype != y.dtype:
raise RuntimeError("x and y must share the same dtype")
xa = as_numpy_view(x)
ya = as_numpy_view(y)
if x.dtype == torch.int32:
return int(_fast_compare_i32(xa, ya))
return int(_fast_compare_i64(xa, ya))
We maintain the same checks as before, but convert the CPU tensors to NumPy arrays so that we can use Numba. We then dispatch to two Numba functions, one each for int64 and int32. For int32, we reinterpret the even prefix as int64 words and take advantage of coalescing by unrolling four words/iteration to check eight int32 values/loop. Similarly, for int64, we compare four elements/loop.
After running uv run modal run ci.py --target tests/kernel/test_radix.py::test_fast_compare_key_perf, we get:
[2026-03-23|18:30:11] INFO LEN= 1024 | fast_compare_key | Torch Impl: 0.010 ms | Old Impl: 0.001 ms | New Impl: 0.003 ms
[2026-03-23|18:30:11] INFO LEN= 16384 | fast_compare_key | Torch Impl: 0.053 ms | Old Impl: 0.005 ms | New Impl: 0.006 ms
[2026-03-23|18:30:11] INFO LEN= 262144 | fast_compare_key | Torch Impl: 0.786 ms | Old Impl: 0.073 ms | New Impl: 0.050 ms
For small n, ours is a bit slower due to overhead. However, at large n, we're 15.72x faster than Torch and 1.46x faster than the original C++ implementation! To be fair, though, since we benchmark using the worst case (i.e., the mismatch is at the very end), our specialized unrolled scan is fully utilized.
Let's move on to store_cache.
store_cache
This kernel is the KV-cache scatter write in the attention path. It's called by MHAKVCache.store_kv() to take the per-token K/V rows for the current batch and write them into cache. As with fast_compare_key, this kernel is almost purely memory-bound.
mini-sglang
# llmeng/kernel_old/store.py
DEFAULT_INDEX_KERNEL_CONFIG = KernelConfig(
num_threads=128, max_occupancy=1, use_pdl=False
)
@functools.cache
def _jit_store_module(
element_size: int,
*,
config: KernelConfig = DEFAULT_INDEX_KERNEL_CONFIG,
) -> Module:
args = make_cpp_args(element_size, *config)
return load_jit(
"store",
*args,
cuda_files=["store.cu"],
cuda_wrappers=[("launch", f"StoreKernel<{args}>::run")],
)
def store_cache(
k_cache: torch.Tensor,
v_cache: torch.Tensor,
indices: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
) -> None:
num_tokens = k_cache.shape[0]
k_cache = k_cache.view(num_tokens, -1)
v_cache = v_cache.view(num_tokens, -1)
element_size = k_cache.shape[1] * k_cache.element_size()
module = _jit_store_module(element_size)
module.launch(k_cache, v_cache, indices, k, v)
// llmeng/kernel_old/csrc/jit/store.cu
struct StoreKernelParams {
void *__restrict__ k_cache;
void *__restrict__ v_cache;
const void *__restrict__ indices;
const void *__restrict__ k;
const void *__restrict__ v;
std::size_t kv_cache_stride;
std::size_t kv_input_stride;
std::size_t length;
};
template <std::size_t kNumThreads, std::size_t kMaxOccupancy, bool kUsePDL,
std::size_t kElementSize, std::integral T>
__global__ __launch_bounds__(kNumThreads, kMaxOccupancy) void //
store_kv_cache(const __grid_constant__ StoreKernelParams params) {
using namespace device;
constexpr auto kWarpPerBlock =
static_cast<unsigned>(kNumThreads / kWarpThreads);
static_assert(kNumThreads % kWarpThreads == 0);
const auto &[k_cache, v_cache, indices, k, v, kv_cache_stride,
kv_input_stride, length] = params;
const auto warp_id =
(threadIdx.x / kWarpThreads) + blockIdx.x * kWarpPerBlock;
PDL::wait<kUsePDL>();
// each warp handles one element
if (warp_id < length) {
const auto pos = static_cast<const T *>(indices)[warp_id];
const auto dst_k = pointer::offset(k_cache, pos * kv_cache_stride);
const auto src_k = pointer::offset(k, warp_id * kv_input_stride);
warp::copy<kElementSize>(dst_k, src_k);
const auto dst_v = pointer::offset(v_cache, pos * kv_cache_stride);
const auto src_v = pointer::offset(v, warp_id * kv_input_stride);
warp::copy<kElementSize>(dst_v, src_v);
}
PDL::launch<kUsePDL>();
}
template <std::size_t element_size, // depends on data type and embedding dim
std::size_t num_threads = 128, // number of threads per block
std::size_t max_concurrency = 1, // max blocks per SM
bool use_pdl = false>
struct StoreKernel {
static void run(const tvm::ffi::TensorView k_cache,
const tvm::ffi::TensorView v_cache,
const tvm::ffi::TensorView indices,
const tvm::ffi::TensorView k, const tvm::ffi::TensorView v) {
using namespace host;
auto D = SymbolicSize{"D"}; // element size
auto L = SymbolicSize{"L"}; // length
auto X = SymbolicSize{"X"}; // stride kv cache
auto Y = SymbolicSize{"Y"}; // stride kv input
auto indices_dtype_ = SymbolicDType{};
auto dtype_ = SymbolicDType{};
auto device_ = SymbolicDevice{};
TensorMatcher({-1, D}) //
.with_strides({X, 1})
.with_device<kDLCUDA>(device_)
.with_dtype(dtype_)
.verify(k_cache)
.verify(v_cache);
TensorMatcher({L, D}) //
.with_strides({Y, 1})
.with_device<kDLCUDA>(device_)
.with_dtype(dtype_)
.verify(k)
.verify(v);
TensorMatcher({L}) //
.with_device<kDLCUDA>(device_)
.with_dtype<int32_t, int64_t>(indices_dtype_)
.verify(indices);
const auto dtype_size = dtype_bytes(dtype_.unwrap());
RuntimeCheck(element_size == dtype_size * D.unwrap());
const auto device = device_.unwrap();
const auto use_int32 = indices_dtype_.unwrap().bits == 32;
const auto length = static_cast<std::size_t>(L.unwrap());
const auto kv_cache_stride = X.unwrap() * dtype_size;
const auto kv_input_stride = Y.unwrap() * dtype_size;
const auto params = StoreKernelParams{
.k_cache = k_cache.data_ptr(),
.v_cache = v_cache.data_ptr(),
.indices = indices.data_ptr(),
.k = k.data_ptr(),
.v = v.data_ptr(),
.kv_cache_stride = kv_cache_stride,
.kv_input_stride = kv_input_stride,
.length = length,
};
constexpr auto kWarpPerBlock = num_threads / 32;
static_assert(num_threads % 32 == 0);
const auto num_blocks = div_ceil(length, kWarpPerBlock);
const auto kernel = use_int32
? store_kv_cache<num_threads, max_concurrency,
use_pdl, element_size, int32_t>
: store_kv_cache<num_threads, max_concurrency,
use_pdl, element_size, int64_t>;
LaunchKernel(num_blocks, num_threads, device)
.with_attr(use_pdl)(kernel, params);
}
};
The CUDA kernel launches a fixed 128-thread kernel with four warps/block. Each warp reads one logical row, then computes two destination rows for K and V, each calling warp::copy<kElementSize>(...).
Before we show our own kernel, we first describe how we change the physical KV cache layout to help us out. Instead of keeping separate K and V buffers, we allocate a single buffer to keep each token's K and V values adjacent in memory. To pull them out separately, we use a row-wide offset for zero-copy strided access.
Onto the kernel.
CuTe-DSL
# llmeng/kernel_new/store.py
NUM_THREADS = 256
MAX_VECTOR_BYTES = 16
def _get_vector_elems(width: int, element_size: int) -> int:
max_vector_elems = max(1, MAX_VECTOR_BYTES // element_size)
vector_elems = max_vector_elems
while vector_elems > 1:
if width % vector_elems == 0 and width // vector_elems <= NUM_THREADS:
return vector_elems
vector_elems //= 2
return 1
def _get_rows_per_block(num_rows: int, tiles_per_row: int) -> int:
rows_per_block = min(NUM_THREADS // tiles_per_row, 8)
while rows_per_block > 1 and num_rows % rows_per_block != 0:
rows_per_block //= 2
return max(rows_per_block, 1)
class _FusedStoreKernel:
def __init__(self, tile_elems: int, tiles_per_row: int, rows_per_block: int):
self.tile_elems = tile_elems
self.tiles_per_row = tiles_per_row
self.rows_per_block = rows_per_block
@cute.jit
def __call__(
self,
src: cute.Tensor,
dst: cute.Tensor,
indices: cute.Tensor,
stream: cuda.CUstream,
) -> None:
tiled_src = tile_last_dim(src, self.tile_elems)
tiled_dst = tile_last_dim(dst, self.tile_elems)
rows, _ = tiled_src.shape[1]
self.kernel(tiled_src, tiled_dst, indices).launch(
grid=(rows // self.rows_per_block, 1, 1),
block=(self.tiles_per_row, self.rows_per_block, 1),
stream=stream,
)
@cute.kernel
def kernel(
self,
tiled_src: cute.Tensor,
tiled_dst: cute.Tensor,
indices: cute.Tensor,
) -> None:
tidx, tidy, _ = cute.arch.thread_idx()
bidx, _, _ = cute.arch.block_idx()
row = bidx * self.rows_per_block + tidy
pos = indices[row]
tiled_dst[(None, (pos, tidx))] = tiled_src[(None, (row, tidx))].load()
class _SplitStoreKernel:
def __init__(self, tile_elems: int, tiles_per_row: int, rows_per_block: int):
self.tile_elems = tile_elems
self.tiles_per_row = tiles_per_row
self.rows_per_block = rows_per_block
@cute.jit
def __call__(
self,
k_src: cute.Tensor,
v_src: cute.Tensor,
k_dst: cute.Tensor,
v_dst: cute.Tensor,
indices: cute.Tensor,
stream: cuda.CUstream,
) -> None:
tiled_k_src = tile_last_dim(k_src, self.tile_elems)
tiled_v_src = tile_last_dim(v_src, self.tile_elems)
tiled_k_dst = tile_last_dim(k_dst, self.tile_elems)
tiled_v_dst = tile_last_dim(v_dst, self.tile_elems)
rows, _ = tiled_k_src.shape[1]
self.kernel(
tiled_k_src,
tiled_v_src,
tiled_k_dst,
tiled_v_dst,
indices,
).launch(
grid=(rows // self.rows_per_block, 1, 1),
block=(self.tiles_per_row, self.rows_per_block, 1),
stream=stream,
)
@cute.kernel
def kernel(
self,
tiled_k_src: cute.Tensor,
tiled_v_src: cute.Tensor,
tiled_k_dst: cute.Tensor,
tiled_v_dst: cute.Tensor,
indices: cute.Tensor,
) -> None:
tidx, tidy, _ = cute.arch.thread_idx()
bidx, _, _ = cute.arch.block_idx()
row = bidx * self.rows_per_block + tidy
pos = indices[row]
tiled_k_dst[(None, (pos, tidx))] = tiled_k_src[(None, (row, tidx))].load()
tiled_v_dst[(None, (pos, tidx))] = tiled_v_src[(None, (row, tidx))].load()
@functools.cache
def _compiled_fused_store(
width: int,
device_index: int,
torch_dtype: torch.dtype,
index_dtype: torch.dtype,
tile_elems: int,
rows_per_block: int,
):
sample_device = torch.device(f"cuda:{device_index}")
sample_src = torch.empty(
(rows_per_block, width), device=sample_device, dtype=torch_dtype
)
sample_dst = torch.empty(
(rows_per_block * 2, width),
device=sample_device,
dtype=torch_dtype,
)
sample_indices = torch.zeros(
(rows_per_block,), device=sample_device, dtype=index_dtype
)
return cute.compile(
_FusedStoreKernel(tile_elems, width // tile_elems, rows_per_block),
as_cute_2d_tensor(sample_src, divisibility=tile_elems),
as_cute_2d_tensor(sample_dst, divisibility=tile_elems),
as_cute_1d_tensor(sample_indices),
get_current_cuda_stream(sample_device),
)
@functools.cache
def _compiled_split_store(
width: int,
device_index: int,
torch_dtype: torch.dtype,
index_dtype: torch.dtype,
tile_elems: int,
rows_per_block: int,
):
sample_device = torch.device(f"cuda:{device_index}")
sample_k_src = torch.empty(
(rows_per_block, width),
device=sample_device,
dtype=torch_dtype,
)
sample_v_src = torch.empty(
(rows_per_block, width),
device=sample_device,
dtype=torch_dtype,
)
sample_k_dst = torch.empty(
(rows_per_block * 2, width),
device=sample_device,
dtype=torch_dtype,
)
sample_v_dst = torch.empty(
(rows_per_block * 2, width),
device=sample_device,
dtype=torch_dtype,
)
sample_indices = torch.zeros(
(rows_per_block,), device=sample_device, dtype=index_dtype
)
return cute.compile(
_SplitStoreKernel(tile_elems, width // tile_elems, rows_per_block),
as_cute_2d_tensor(sample_k_src, divisibility=tile_elems),
as_cute_2d_tensor(sample_v_src, divisibility=tile_elems),
as_cute_2d_tensor(sample_k_dst, divisibility=tile_elems),
as_cute_2d_tensor(sample_v_dst, divisibility=tile_elems),
as_cute_1d_tensor(sample_indices),
get_current_cuda_stream(sample_device),
)
def _get_adjacent_pair_view(
first: torch.Tensor,
second: torch.Tensor,
) -> torch.Tensor | None:
if first.shape != second.shape or first.ndim != 2:
return None
if first.device != second.device or first.dtype != second.dtype:
return None
if first.stride(-1) != 1 or second.stride(-1) != 1:
return None
if first.stride(0) != second.stride(0):
return None
width = first.shape[1]
if first.stride(0) < width * 2:
return None
if first.untyped_storage().data_ptr() != second.untyped_storage().data_ptr():
return None
if second.storage_offset() != first.storage_offset() + width:
return None
return first.as_strided(
(first.shape[0], width * 2),
(first.stride(0), 1),
first.storage_offset(),
)
def store_cache(
k_cache: torch.Tensor,
v_cache: torch.Tensor,
indices: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
) -> None:
num_tokens = k_cache.shape[0]
k_cache = k_cache.view(num_tokens, -1)
v_cache = v_cache.view(num_tokens, -1)
_validate_inputs(k_cache, v_cache, indices, k, v)
total = k.numel()
if total == 0:
return
stream = get_current_cuda_stream(k_cache.device)
num_rows = k.shape[0]
fused_cache = _get_adjacent_pair_view(k_cache, v_cache)
fused_kv = _get_adjacent_pair_view(k, v)
if fused_cache is not None and fused_kv is not None:
tile_elems = _get_vector_elems(fused_cache.shape[1], fused_cache.element_size())
rows_per_block = _get_rows_per_block(
num_rows,
fused_cache.shape[1] // tile_elems,
)
_compiled_fused_store(
fused_cache.shape[1],
k_cache.device.index or 0,
fused_cache.dtype,
indices.dtype,
tile_elems,
rows_per_block,
)(
fused_kv,
fused_cache,
indices,
stream,
)
return
tile_elems = _get_vector_elems(k.shape[1], k.element_size())
rows_per_block = _get_rows_per_block(num_rows, k.shape[1] // tile_elems)
_compiled_split_store(
k.shape[1],
k_cache.device.index or 0,
k.dtype,
indices.dtype,
tile_elems,
rows_per_block,
)(
k,
v,
k_cache,
v_cache,
indices,
stream,
)
In the best case, where K and V are adjacent in both cache and input memory, we reinterpret them as a single 2D matrix and do a single tiled scatter-copy. Otherwise, we do two row-tile stores/thread. We then target up to 16 bytes/mem-op to move full aligned vectors: fp16/bf16 -> 8 elements/tile, fp32 -> 4, etc. Finally, the actual kernel uses tidy to index the row within the block, and tidx to index the vector tile within the row.
I also tried a CuTile version for Blackwell:
CuTile
# llmeng/kernel_new/store_blackwell_tile.py
MAX_ROW_TILE = 8
def _get_row_tile(num_rows: int) -> int:
for row_tile in (MAX_ROW_TILE, 4, 2):
if num_rows % row_tile == 0:
return row_tile
return 1
def _get_adjacent_pair_view(
first: torch.Tensor,
second: torch.Tensor,
) -> torch.Tensor | None:
if first.shape != second.shape or first.ndim != 2:
return None
if first.device != second.device or first.dtype != second.dtype:
return None
if first.stride(-1) != 1 or second.stride(-1) != 1:
return None
if first.stride(0) != second.stride(0):
return None
width = first.shape[1]
if first.stride(0) < width * 2:
return None
if first.untyped_storage().data_ptr() != second.untyped_storage().data_ptr():
return None
if second.storage_offset() != first.storage_offset() + width:
return None
return first.as_strided(
(first.shape[0], width * 2),
(first.stride(0), 1),
first.storage_offset(),
)
@functools.cache
def _get_store_kernel(
*,
width: int,
row_tile: int,
index_dtype: torch.dtype,
):
import cuda.tile as ct
globals()["ct"] = ct
tile_index_dtype = ct.int64 if index_dtype == torch.int64 else ct.int32
def _broadcast_rows(tile):
return ct.broadcast_to(ct.reshape(tile, (row_tile, 1)), (row_tile, width))
def _broadcast_cols(tile):
return ct.broadcast_to(ct.reshape(tile, (1, width)), (row_tile, width))
@ct.kernel
def _kernel(src, dst, indices):
bid_row = ct.bid(0)
row_offsets = ct.arange(row_tile, dtype=tile_index_dtype) + bid_row * row_tile
col_offsets = ct.arange(width, dtype=tile_index_dtype)
dst_rows = ct.gather(indices, row_offsets, check_bounds=False, latency=1)
values = ct.gather(
src,
(_broadcast_rows(row_offsets), _broadcast_cols(col_offsets)),
check_bounds=False,
latency=10,
)
ct.scatter(
dst,
(_broadcast_rows(dst_rows), _broadcast_cols(col_offsets)),
values,
check_bounds=False,
latency=10,
)
return _kernel
def _run_store(
src: torch.Tensor,
dst: torch.Tensor,
indices: torch.Tensor,
) -> None:
import cuda.tile as ct
row_tile = _get_row_tile(src.shape[0])
grid = (src.shape[0] // row_tile, 1, 1)
stream = torch.cuda.current_stream(device=src.device)
ct.launch(
stream,
grid,
_get_store_kernel(
width=src.shape[1],
row_tile=row_tile,
index_dtype=indices.dtype,
),
(src, dst, indices),
)
def store_cache(
k_cache: torch.Tensor,
v_cache: torch.Tensor,
indices: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
) -> None:
num_tokens = k_cache.shape[0]
k_cache = k_cache.view(num_tokens, -1)
v_cache = v_cache.view(num_tokens, -1)
_validate_inputs(k_cache, v_cache, indices, k, v)
if k.numel() == 0:
return
if not supports_store_cache(k_cache, v_cache, indices, k, v):
raise RuntimeError(
"Blackwell cuTile store requires SM100+ CUDA tensors with matching dtypes"
)
fused_cache = _get_adjacent_pair_view(k_cache, v_cache)
fused_kv = _get_adjacent_pair_view(k, v)
if fused_cache is not None and fused_kv is not None:
_run_store(fused_kv, fused_cache, indices)
return
_run_store(k, k_cache, indices)
_run_store(v, v_cache, indices)
After running uv run modal run ci.py --target tests/kernel/test_store.py, we get:
[2026-03-25|00:32:47] INFO BS= 1 | Torch Impl: 0.002 ms | 0.273 GB/s | Old Impl: 0.001 ms | 0.474 GB/s | New Impl: 0.001 ms | 0.496 GB/s
[2026-03-25|00:32:49] INFO BS= 2 | Torch Impl: 0.002 ms | 0.456 GB/s | Old Impl: 0.001 ms | 0.825 GB/s | New Impl: 0.001 ms | 0.742 GB/s
[2026-03-25|00:32:49] INFO BS= 4 | Torch Impl: 0.002 ms | 0.904 GB/s | Old Impl: 0.001 ms | 1.709 GB/s | New Impl: 0.001 ms | 1.433 GB/s
[2026-03-25|00:32:50] INFO BS= 8 | Torch Impl: 0.002 ms | 1.850 GB/s | Old Impl: 0.001 ms | 3.306 GB/s | New Impl: 0.001 ms | 2.896 GB/s
[2026-03-25|00:32:50] INFO BS= 16 | Torch Impl: 0.002 ms | 3.565 GB/s | Old Impl: 0.001 ms | 6.419 GB/s | New Impl: 0.001 ms | 5.850 GB/s
[2026-03-25|00:32:50] INFO BS= 32 | Torch Impl: 0.002 ms | 6.961 GB/s | Old Impl: 0.001 ms | 12.955 GB/s | New Impl: 0.001 ms | 11.199 GB/s
[2026-03-25|00:32:50] INFO BS= 64 | Torch Impl: 0.002 ms | 13.962 GB/s | Old Impl: 0.001 ms | 24.734 GB/s | New Impl: 0.001 ms | 21.937 GB/s
[2026-03-25|00:32:50] INFO BS= 128 | Torch Impl: 0.002 ms | 27.111 GB/s | Old Impl: 0.001 ms | 48.867 GB/s | New Impl: 0.002 ms | 42.079 GB/s
[2026-03-25|00:32:50] INFO BS= 256 | Torch Impl: 0.003 ms | 51.503 GB/s | Old Impl: 0.001 ms | 95.123 GB/s | New Impl: 0.002 ms | 86.177 GB/s
[2026-03-25|00:32:50] INFO BS= 512 | Torch Impl: 0.003 ms | 104.543 GB/s | Old Impl: 0.001 ms | 176.058 GB/s | New Impl: 0.002 ms | 165.495 GB/s
[2026-03-25|00:32:50] INFO BS= 1024 | Torch Impl: 0.003 ms | 197.326 GB/s | Old Impl: 0.001 ms | 355.710 GB/s | New Impl: 0.002 ms | 310.479 GB/s
[2026-03-25|00:32:50] INFO BS= 2048 | Torch Impl: 0.003 ms | 333.788 GB/s | Old Impl: 0.002 ms | 622.020 GB/s | New Impl: 0.002 ms | 627.019 GB/s
[2026-03-25|00:32:50] INFO BS= 4096 | Torch Impl: 0.004 ms | 469.657 GB/s | Old Impl: 0.002 ms | 1102.186 GB/s | New Impl: 0.002 ms | 1007.162 GB/s
[2026-03-25|00:32:50] INFO BS= 8192 | Torch Impl: 0.007 ms | 604.910 GB/s | Old Impl: 0.003 ms | 1660.821 GB/s | New Impl: 0.003 ms | 1618.573 GB/s
[2026-03-25|00:32:50] INFO BS= 16384 | Torch Impl: 0.012 ms | 706.740 GB/s | Old Impl: 0.004 ms | 2238.634 GB/s | New Impl: 0.004 ms | 2347.488 GB/s
[2026-03-25|00:32:50] INFO BS= 32768 | Torch Impl: 0.022 ms | 760.212 GB/s | Old Impl: 0.007 ms | 2579.396 GB/s | New Impl: 0.006 ms | 2625.247 GB/s
[2026-03-25|00:32:34] INFO [blackwell] BS= 1 | Torch Impl: 0.003 ms | 0.204 GB/s | Old Impl: 0.001 ms | 0.345 GB/s | New Impl: 0.001 ms | 0.377 GB/s | cuTile Impl: 0.001 ms | 0.396 GB/s
[2026-03-25|00:32:34] INFO [blackwell] BS= 2 | Torch Impl: 0.002 ms | 0.448 GB/s | Old Impl: 0.001 ms | 0.694 GB/s | New Impl: 0.001 ms | 0.691 GB/s | cuTile Impl: 0.002 ms | 0.413 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 4 | Torch Impl: 0.002 ms | 0.820 GB/s | Old Impl: 0.002 ms | 1.212 GB/s | New Impl: 0.001 ms | 1.386 GB/s | cuTile Impl: 0.002 ms | 0.893 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 8 | Torch Impl: 0.002 ms | 1.639 GB/s | Old Impl: 0.001 ms | 2.754 GB/s | New Impl: 0.001 ms | 2.738 GB/s | cuTile Impl: 0.002 ms | 1.653 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 16 | Torch Impl: 0.002 ms | 3.279 GB/s | Old Impl: 0.002 ms | 4.851 GB/s | New Impl: 0.001 ms | 5.533 GB/s | cuTile Impl: 0.002 ms | 3.449 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 32 | Torch Impl: 0.003 ms | 6.060 GB/s | Old Impl: 0.002 ms | 10.177 GB/s | New Impl: 0.001 ms | 11.070 GB/s | cuTile Impl: 0.002 ms | 6.611 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 64 | Torch Impl: 0.003 ms | 12.118 GB/s | Old Impl: 0.001 ms | 22.117 GB/s | New Impl: 0.002 ms | 19.753 GB/s | cuTile Impl: 0.002 ms | 13.115 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 128 | Torch Impl: 0.003 ms | 24.254 GB/s | Old Impl: 0.002 ms | 38.817 GB/s | New Impl: 0.002 ms | 39.024 GB/s | cuTile Impl: 0.003 ms | 24.427 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 256 | Torch Impl: 0.003 ms | 45.360 GB/s | Old Impl: 0.002 ms | 77.767 GB/s | New Impl: 0.002 ms | 78.528 GB/s | cuTile Impl: 0.003 ms | 48.479 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 512 | Torch Impl: 0.003 ms | 90.790 GB/s | Old Impl: 0.002 ms | 157.085 GB/s | New Impl: 0.002 ms | 157.146 GB/s | cuTile Impl: 0.003 ms | 90.780 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 1024 | Torch Impl: 0.003 ms | 169.659 GB/s | Old Impl: 0.002 ms | 281.270 GB/s | New Impl: 0.002 ms | 312.195 GB/s | cuTile Impl: 0.003 ms | 193.962 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 2048 | Torch Impl: 0.004 ms | 254.746 GB/s | Old Impl: 0.002 ms | 623.558 GB/s | New Impl: 0.002 ms | 557.184 GB/s | cuTile Impl: 0.003 ms | 360.563 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 4096 | Torch Impl: 0.006 ms | 350.704 GB/s | Old Impl: 0.002 ms | 1005.616 GB/s | New Impl: 0.002 ms | 1112.854 GB/s | cuTile Impl: 0.003 ms | 678.076 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 8192 | Torch Impl: 0.010 ms | 400.783 GB/s | Old Impl: 0.002 ms | 1780.386 GB/s | New Impl: 0.002 ms | 1692.562 GB/s | cuTile Impl: 0.004 ms | 1190.806 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 16384 | Torch Impl: 0.019 ms | 449.100 GB/s | Old Impl: 0.004 ms | 2367.416 GB/s | New Impl: 0.003 ms | 2748.705 GB/s | cuTile Impl: 0.004 ms | 1940.657 GB/s
[2026-03-25|00:32:35] INFO [blackwell] BS= 32768 | Torch Impl: 0.036 ms | 470.125 GB/s | Old Impl: 0.006 ms | 3022.878 GB/s | New Impl: 0.005 ms | 3723.636 GB/s | cuTile Impl: 0.007 ms | 2551.901 GB/s
As before, we suffer from a slight overhead for small n, but at large n we outperform the original! On Hopper (the default GPU type for non-Blackwell tests), we achieve 3.45x the bandwidth of Torch and a modest 1.01x improvement over the original CUDA implementation. On Blackwell, the improvement of our CuTe-DSL implementation is much more pronounced: we achieve 7.92x the bandwidth of Torch and a 1.23x improvement over the original CUDA implementation. Note that the CuTile version is much slower than the CuTe-DSL one, probably because it treats the problem as a generic irregular gather/scatter problem vs. the specialized row-copy CuTe-DSL version.
Onto indexing.
indexing
This kernel is a vocab-row gather called by VocabParallelEmbedding.forward() to turn token ids into embedding vectors. Yet again, this is purely memory-bound.
mini-sglang
# llmeng/kernel_old/index.py
DEFAULT_INDEX_KERNEL_CONFIG = KernelConfig(
num_threads=128, max_occupancy=1, use_pdl=False
)
@functools.cache
def _jit_index_module(
element_size: int,
*,
num_splits: int = 1,
config: KernelConfig = DEFAULT_INDEX_KERNEL_CONFIG,
) -> Module:
args = make_cpp_args(element_size, num_splits, *config)
return load_jit(
"index",
*args,
cuda_files=["index.cu"],
cuda_wrappers=[("launch", f"IndexKernel<{args}>::run")],
)
def indexing(
weights: torch.Tensor,
indices: torch.Tensor,
*,
output: torch.Tensor | None = None,
vocab_range: Tuple[int, int] | None = None, # (start, length)
) -> torch.Tensor:
if output is None:
output = weights.new_empty(indices.shape[0], weights.shape[1])
element_size = weights.shape[1] * weights.element_size()
if element_size % 2048 == 0:
num_splits = 4
elif element_size % 1024 == 0:
num_splits = 2
else:
num_splits = 1
module = _jit_index_module(element_size, num_splits=num_splits)
module.launch(weights, indices, output, vocab_range)
return output
// llmeng/kernel_old/csrc/jit/index.cu
struct IndexKernelParams {
void *__restrict__ output;
const void *__restrict__ weight;
const void *__restrict__ indice;
std::size_t num_warps;
};
struct MaskedKernelParams {
IndexKernelParams params;
std::size_t start;
std::size_t length;
};
template <std::size_t kNumThreads, std::size_t kMaxOccupancy, bool kUsePDL,
std::size_t kElementSize, std::size_t kNumSplits, std::integral T>
__global__ __launch_bounds__(kNumThreads, kMaxOccupancy) void //
index_kernel(const __grid_constant__ IndexKernelParams params) {
using namespace device;
constexpr auto kSize = kElementSize;
constexpr auto kSizePerWarp = kSize / kNumSplits;
constexpr auto kWarpPerBlock = static_cast<unsigned>(kNumThreads / 32);
static_assert(kNumThreads % 32 == 0);
static_assert(std::has_single_bit(kNumSplits));
static_assert(kElementSize % kNumSplits == 0);
const auto &[output, weight, indices_, num_warps] = params;
const auto indices = static_cast<const T *>(indices_);
const auto warp_id =
(threadIdx.x / kWarpThreads) + blockIdx.x * kWarpPerBlock;
PDL::wait<kUsePDL>();
if (warp_id < num_warps) {
const auto pos = indices[warp_id / kNumSplits];
const auto dst = pointer::offset(output, warp_id * kSizePerWarp);
const auto src = pointer::offset(weight, pos * kSize,
(warp_id % kNumSplits) * kSizePerWarp);
warp::copy<kSizePerWarp>(dst, src);
}
PDL::launch<kUsePDL>();
}
template <std::size_t kNumThreads, std::size_t kMaxOccupancy, bool kUsePDL,
std::size_t kElementSize, std::size_t kNumSplits, std::integral T>
__global__ __launch_bounds__(kNumThreads, kMaxOccupancy) void //
masked_index_kernel(
const __grid_constant__ MaskedKernelParams mask_params) {
using namespace device;
constexpr auto kSize = kElementSize;
constexpr auto kSizePerWarp = kSize / kNumSplits;
constexpr auto kWarpPerBlock = static_cast<unsigned>(kNumThreads / 32);
static_assert(kNumThreads % 32 == 0);
static_assert(std::has_single_bit(kNumSplits));
static_assert(kElementSize % kNumSplits == 0);
const auto &[params, start, length] = mask_params;
const auto &[output, weight, indices_, num_warps] = params;
const auto indices = static_cast<const T *>(indices_);
const auto warp_id =
(threadIdx.x / kWarpThreads) + blockIdx.x * kWarpPerBlock;
PDL::wait<kUsePDL>();
if (warp_id < num_warps) {
const auto pos = indices[warp_id / kNumSplits] - start;
const auto dst = pointer::offset(output, warp_id * kSizePerWarp);
if (pos < length) {
const auto src = pointer::offset(weight, pos * kSize,
(warp_id % kNumSplits) * kSizePerWarp);
warp::copy<kSizePerWarp>(dst, src);
} else {
warp::reset<kSizePerWarp>(dst);
}
}
PDL::launch<kUsePDL>();
}
template <std::size_t element_size, // depends on data type and embedding dim
std::size_t num_splits = 1, // how many warps handles one element
std::size_t num_threads = 128, // number of threads per block
std::size_t max_concurrency = 1, // max blocks per SM
bool use_pdl = false>
struct IndexKernel {
static void run(const tvm::ffi::TensorView weights,
const tvm::ffi::TensorView indices,
const tvm::ffi::TensorView output,
tvm::ffi::Optional<tvm::ffi::Tuple<int, int>> mask_opts) {
using namespace host;
auto D = SymbolicSize{"D"}; // embedding size
auto L = SymbolicSize{"L"}; // num indices
auto device_ = SymbolicDevice{};
auto weights_dtype_ = SymbolicDType{};
auto indices_dtype_ = SymbolicDType{};
TensorMatcher({-1, D}) //
.with_dtype(weights_dtype_)
.with_device<kDLCUDA>(device_)
.verify(weights);
TensorMatcher({L, D}) //
.with_dtype(weights_dtype_)
.with_device<kDLCUDA>(device_)
.verify(output);
TensorMatcher({L}) //
.with_dtype<int32_t, int64_t>(indices_dtype_)
.with_device<kDLCUDA>(device_)
.verify(indices);
const auto device = device_.unwrap();
const auto use_int32 = indices_dtype_.unwrap().bits == 32;
const auto num_indices = L.unwrap();
const auto entry_size = dtype_bytes(weights_dtype_.unwrap()) * D.unwrap();
RuntimeCheck(entry_size == element_size,
"IndexKernel: element_size mismatch.");
constexpr auto kWarpPerBlock = num_threads / 32;
const auto num_warps = num_splits * num_indices;
const auto num_blocks = div_ceil(num_warps, kWarpPerBlock);
const auto params = IndexKernelParams{
.output = static_cast<char *>(output.data_ptr()),
.weight = static_cast<const char *>(weights.data_ptr()),
.indice = indices.data_ptr(),
.num_warps = num_warps,
};
if (mask_opts.has_value()) {
const auto &obj = mask_opts.value();
const auto [start, length] = obj;
const auto m_params = MaskedKernelParams{
.params = params,
.start = static_cast<std::size_t>(start),
.length = static_cast<std::size_t>(length),
};
const auto kernel =
use_int32 ? masked_index_kernel<num_threads, max_concurrency, use_pdl,
element_size, num_splits, int32_t>
: masked_index_kernel<num_threads, max_concurrency, use_pdl,
element_size, num_splits, int64_t>;
LaunchKernel(num_blocks, num_threads, device)
.with_attr(use_pdl)(kernel, m_params);
} else {
const auto kernel =
use_int32 ? index_kernel<num_threads, max_concurrency, use_pdl,
element_size, num_splits, int32_t>
: index_kernel<num_threads, max_concurrency, use_pdl,
element_size, num_splits, int64_t>;
LaunchKernel(num_blocks, num_threads, device)
.with_attr(use_pdl)(kernel, params);
}
}
};
There are two kernels, one for the unmasked case (i.e., when no vocab range is specified) and another for the masked case. Like the previous store_cache, each warp copies one contiguous row. To mask out rows, it utilizes warp::reset<kSizePerWarp>(). Another idea borrowed from store_cache is splitting wide embedding rows across multiple warps.
CuTe-DSL
# llmeng/kernel_new/index.py
WARP_SIZE = 32
NUM_THREADS = 128
WARPS_PER_BLOCK = NUM_THREADS // WARP_SIZE
MAX_VECTOR_BYTES = 16
class _IndexKernel:
def __init__(
self,
tile_elems: int,
num_splits: int,
tiles_per_split: int,
) -> None:
self.tile_elems = tile_elems
self.num_splits = num_splits
self.tiles_per_split = tiles_per_split
self.split_shift = num_splits.bit_length() - 1
self.split_mask = num_splits - 1
@cute.jit
def __call__(
self,
weights: cute.Tensor,
indices: cute.Tensor,
output: cute.Tensor,
stream: cuda.CUstream,
) -> None:
tiled_weights = tile_last_dim(weights, self.tile_elems)
tiled_output = tile_last_dim(output, self.tile_elems)
rows, _ = tiled_output.shape[1]
num_warps = rows * self.num_splits
self.kernel(tiled_weights, indices, tiled_output).launch(
grid=((num_warps + WARPS_PER_BLOCK - 1) // WARPS_PER_BLOCK, 1, 1),
block=(NUM_THREADS, 1, 1),
stream=stream,
)
@cute.kernel
def kernel(
self,
tiled_weights: cute.Tensor,
indices: cute.Tensor,
tiled_output: cute.Tensor,
) -> None:
tidx, _, _ = cute.arch.thread_idx()
bidx, _, _ = cute.arch.block_idx()
lane = tidx % WARP_SIZE
warp_idx = tidx // WARP_SIZE
logical_warp = bidx * WARPS_PER_BLOCK + warp_idx
row = logical_warp >> self.split_shift
rows, _ = tiled_output.shape[1]
if row < rows:
split_id = logical_warp & self.split_mask
tile_base = split_id * self.tiles_per_split
src_row = indices[row]
for tile_offset in range(lane, self.tiles_per_split, WARP_SIZE):
tile = tile_base + tile_offset
src_tile = tiled_weights[(None, (src_row, tile))]
dst_tile = tiled_output[(None, (row, tile))]
dst_tile.store(src_tile.load())
class _MaskedIndexKernel:
def __init__(
self,
tile_elems: int,
num_splits: int,
tiles_per_split: int,
) -> None:
self.tile_elems = tile_elems
self.num_splits = num_splits
self.tiles_per_split = tiles_per_split
self.split_shift = num_splits.bit_length() - 1
self.split_mask = num_splits - 1
@cute.jit
def __call__(
self,
weights: cute.Tensor,
indices: cute.Tensor,
output: cute.Tensor,
start: int,
length: int,
stream: cuda.CUstream,
) -> None:
tiled_weights = tile_last_dim(weights, self.tile_elems)
tiled_output = tile_last_dim(output, self.tile_elems)
rows, _ = tiled_output.shape[1]
num_warps = rows * self.num_splits
self.kernel(
tiled_weights,
indices,
tiled_output,
start,
length,
).launch(
grid=((num_warps + WARPS_PER_BLOCK - 1) // WARPS_PER_BLOCK, 1, 1),
block=(NUM_THREADS, 1, 1),
stream=stream,
)
@cute.kernel
def kernel(
self,
tiled_weights: cute.Tensor,
indices: cute.Tensor,
tiled_output: cute.Tensor,
start: int,
length: int,
) -> None:
tidx, _, _ = cute.arch.thread_idx()
bidx, _, _ = cute.arch.block_idx()
lane = tidx % WARP_SIZE
warp_idx = tidx // WARP_SIZE
logical_warp = bidx * WARPS_PER_BLOCK + warp_idx
row = logical_warp >> self.split_shift
rows, _ = tiled_output.shape[1]
if row < rows:
split_id = logical_warp & self.split_mask
tile_base = split_id * self.tiles_per_split
src_row = indices[row] - start
valid = 0 <= src_row < length
if valid:
for tile_offset in range(lane, self.tiles_per_split, WARP_SIZE):
tile = tile_base + tile_offset
dst_tile = tiled_output[(None, (row, tile))]
src_tile = tiled_weights[(None, (src_row, tile))]
dst_tile.store(src_tile.load())
else:
for tile_offset in range(lane, self.tiles_per_split, WARP_SIZE):
tile = tile_base + tile_offset
dst_tile = tiled_output[(None, (row, tile))]
dst_tile.fill(0)
@functools.cache
def _compiled_index(
width: int,
device_index: int,
torch_dtype: torch.dtype,
index_dtype: torch.dtype,
tile_elems: int,
num_splits: int,
):
sample_device = torch.device(f"cuda:{device_index}")
sample_weights = torch.empty((2, width), device=sample_device, dtype=torch_dtype)
sample_indices = torch.zeros((1,), device=sample_device, dtype=index_dtype)
sample_output = torch.empty((1, width), device=sample_device, dtype=torch_dtype)
return cute.compile(
_IndexKernel(tile_elems, num_splits, (width // tile_elems) // num_splits),
as_cute_2d_tensor(sample_weights, divisibility=tile_elems),
as_cute_1d_tensor(sample_indices),
as_cute_2d_tensor(sample_output, divisibility=tile_elems),
get_current_cuda_stream(sample_device),
)
@functools.cache
def _compiled_masked_index(
width: int,
device_index: int,
torch_dtype: torch.dtype,
index_dtype: torch.dtype,
tile_elems: int,
num_splits: int,
):
sample_device = torch.device(f"cuda:{device_index}")
sample_weights = torch.empty((2, width), device=sample_device, dtype=torch_dtype)
sample_indices = torch.zeros((1,), device=sample_device, dtype=index_dtype)
sample_output = torch.empty((1, width), device=sample_device, dtype=torch_dtype)
return cute.compile(
_MaskedIndexKernel(tile_elems, num_splits, (width // tile_elems) // num_splits),
as_cute_2d_tensor(sample_weights, divisibility=tile_elems),
as_cute_1d_tensor(sample_indices),
as_cute_2d_tensor(sample_output, divisibility=tile_elems),
0,
1,
get_current_cuda_stream(sample_device),
)
def _get_num_splits(width: int, element_size: int) -> int:
row_bytes = width * element_size
if row_bytes % 2048 == 0:
return 4
if row_bytes % 1024 == 0:
return 2
return 1
def _get_tile_elems(
weights: torch.Tensor,
output: torch.Tensor,
*,
num_splits: int,
) -> int:
max_alignment = min(
get_tensor_alignment(weights, max_alignment=MAX_VECTOR_BYTES),
get_tensor_alignment(output, max_alignment=MAX_VECTOR_BYTES),
)
vector_elems = max(
1, min(MAX_VECTOR_BYTES, max_alignment) // weights.element_size()
)
while vector_elems > 1:
if weights.shape[1] % vector_elems == 0:
tiles_per_row = weights.shape[1] // vector_elems
if tiles_per_row % num_splits == 0:
return vector_elems
vector_elems //= 2
return 1
def indexing(
weights: torch.Tensor,
indices: torch.Tensor,
*,
output: torch.Tensor | None = None,
vocab_range: Tuple[int, int] | None = None, # (start, length)
) -> torch.Tensor:
if output is None:
output = weights.new_empty(indices.shape[0], weights.shape[1])
_validate_inputs(weights, indices, output)
total = output.numel()
if total == 0:
return output
num_splits = _get_num_splits(weights.shape[1], weights.element_size())
tile_elems = _get_tile_elems(weights, output, num_splits=num_splits)
stream = get_current_cuda_stream(weights.device)
if vocab_range is None:
_compiled_index(
weights.shape[1],
weights.device.index or 0,
weights.dtype,
indices.dtype,
tile_elems,
num_splits,
)(
weights,
indices,
output,
stream,
)
else:
start, length = vocab_range
_compiled_masked_index(
weights.shape[1],
weights.device.index or 0,
weights.dtype,
indices.dtype,
tile_elems,
num_splits,
)(
weights,
indices,
output,
int(start),
int(length),
stream,
)
return output
We use a similar trick from store_cache here: four warps/block and 16-byte vector tiles for coalesced copies. row = logical_warp >> split_shift picks which output row for the warp to work on, while split_id = logical_warp & split_mask picks the contiguous segment of the row. Inside the warp, each lane strides over the tiles for that split (i.e., lane 0 handles tile 0, 32, 64, etc., lane 1 handles 1, 33, 65, etc.). The masked kernel simply adds another per-row branch for invalid source row values.
We also have a CuTile version:
CuTile
# llmeng/kernel_new/index_blackwell_tile.py
ROW_TILE = 8
COL_TILE = 256
@functools.cache
def _get_index_kernel(index_dtype: torch.dtype):
import cuda.tile as ct
globals()["ct"] = ct
tile_index_dtype = ct.int64 if index_dtype == torch.int64 else ct.int32
def _broadcast_rows(tile):
return ct.broadcast_to(ct.reshape(tile, (ROW_TILE, 1)), (ROW_TILE, COL_TILE))
def _broadcast_cols(tile):
return ct.broadcast_to(ct.reshape(tile, (1, COL_TILE)), (ROW_TILE, COL_TILE))
@ct.kernel
def _kernel(weights, indices, output):
bid_row = ct.bid(0)
bid_col = ct.bid(1)
row_offsets = ct.arange(ROW_TILE, dtype=tile_index_dtype) + bid_row * ROW_TILE
col_offsets = ct.arange(COL_TILE, dtype=tile_index_dtype) + bid_col * COL_TILE
gathered_rows = ct.gather(indices, row_offsets, padding_value=0)
values = ct.gather(
weights,
(_broadcast_rows(gathered_rows), _broadcast_cols(col_offsets)),
padding_value=0,
check_bounds=True,
)
ct.scatter(
output,
(_broadcast_rows(row_offsets), _broadcast_cols(col_offsets)),
values,
check_bounds=True,
)
return _kernel
@functools.cache
def _get_masked_index_kernel(index_dtype: torch.dtype):
import cuda.tile as ct
globals()["ct"] = ct
tile_index_dtype = ct.int64 if index_dtype == torch.int64 else ct.int32
def _broadcast_rows(tile):
return ct.broadcast_to(ct.reshape(tile, (ROW_TILE, 1)), (ROW_TILE, COL_TILE))
def _broadcast_cols(tile):
return ct.broadcast_to(ct.reshape(tile, (1, COL_TILE)), (ROW_TILE, COL_TILE))
@ct.kernel
def _kernel(weights, indices, output, start: int, length: int):
bid_row = ct.bid(0)
bid_col = ct.bid(1)
row_offsets = ct.arange(ROW_TILE, dtype=tile_index_dtype) + bid_row * ROW_TILE
col_offsets = ct.arange(COL_TILE, dtype=tile_index_dtype) + bid_col * COL_TILE
gathered_rows = ct.gather(indices, row_offsets, padding_value=0) - start
valid_rows = (gathered_rows >= 0) & (gathered_rows < length)
safe_rows = ct.where(valid_rows, gathered_rows, tile_index_dtype(-1))
values = ct.gather(
weights,
(_broadcast_rows(safe_rows), _broadcast_cols(col_offsets)),
padding_value=0,
check_bounds=True,
)
ct.scatter(
output,
(_broadcast_rows(row_offsets), _broadcast_cols(col_offsets)),
values,
check_bounds=True,
)
return _kernel
def run_indexing(
weights: torch.Tensor,
indices: torch.Tensor,
output: torch.Tensor,
*,
vocab_range: Tuple[int, int] | None = None,
) -> torch.Tensor:
import cuda.tile as ct
grid = (
ct.cdiv(output.shape[0], ROW_TILE),
ct.cdiv(output.shape[1], COL_TILE),
1,
)
stream = torch.cuda.current_stream(device=weights.device)
if vocab_range is None:
ct.launch(
stream,
grid,
_get_index_kernel(indices.dtype),
(weights, indices, output),
)
else:
start, length = vocab_range
ct.launch(
stream,
grid,
_get_masked_index_kernel(indices.dtype),
(weights, indices, output, int(start), int(length)),
)
return output
After running uv run modal run ci.py --target tests/kernel/test_index.py, we get:
[2026-03-25|01:11:00] INFO BS= 1 | Torch Impl: 0.003 ms | 2.996 GB/s | Old Impl: 0.002 ms | 4.399 GB/s | New Impl: 0.002 ms | 4.814 GB/s
[2026-03-25|01:11:00] INFO BS= 2 | Torch Impl: 0.004 ms | 4.678 GB/s | Old Impl: 0.002 ms | 7.446 GB/s | New Impl: 0.001 ms | 11.191 GB/s
[2026-03-25|01:11:00] INFO BS= 4 | Torch Impl: 0.004 ms | 7.921 GB/s | Old Impl: 0.002 ms | 15.026 GB/s | New Impl: 0.002 ms | 19.512 GB/s
[2026-03-25|01:11:00] INFO BS= 8 | Torch Impl: 0.006 ms | 11.764 GB/s | Old Impl: 0.002 ms | 31.688 GB/s | New Impl: 0.002 ms | 34.624 GB/s
[2026-03-25|01:11:00] INFO BS= 16 | Torch Impl: 0.009 ms | 15.202 GB/s | Old Impl: 0.002 ms | 62.774 GB/s | New Impl: 0.002 ms | 76.675 GB/s
[2026-03-25|01:11:00] INFO BS= 32 | Torch Impl: 0.003 ms | 90.790 GB/s | Old Impl: 0.002 ms | 114.302 GB/s | New Impl: 0.002 ms | 140.756 GB/s
[2026-03-25|01:11:00] INFO BS= 64 | Torch Impl: 0.003 ms | 181.560 GB/s | Old Impl: 0.002 ms | 230.631 GB/s | New Impl: 0.002 ms | 278.261 GB/s
[2026-03-25|01:11:00] INFO BS= 128 | Torch Impl: 0.003 ms | 360.286 GB/s | Old Impl: 0.002 ms | 457.207 GB/s | New Impl: 0.002 ms | 501.961 GB/s
[2026-03-25|01:11:00] INFO BS= 256 | Torch Impl: 0.003 ms | 673.823 GB/s | Old Impl: 0.002 ms | 915.052 GB/s | New Impl: 0.002 ms | 922.393 GB/s
[2026-03-25|01:11:00] INFO BS= 512 | Torch Impl: 0.004 ms | 1184.029 GB/s | Old Impl: 0.003 ms | 1563.172 GB/s | New Impl: 0.002 ms | 1692.781 GB/s
[2026-03-25|01:11:00] INFO BS= 1024 | Torch Impl: 0.005 ms | 1853.394 GB/s | Old Impl: 0.003 ms | 2694.460 GB/s | New Impl: 0.003 ms | 2543.853 GB/s
[2026-03-25|01:11:00] INFO BS= 2048 | Torch Impl: 0.006 ms | 2796.501 GB/s | Old Impl: 0.004 ms | 3863.866 GB/s | New Impl: 0.005 ms | 3562.223 GB/s
[2026-03-25|01:11:00] INFO BS= 4096 | Torch Impl: 0.010 ms | 3297.409 GB/s | Old Impl: 0.008 ms | 4105.783 GB/s | New Impl: 0.008 ms | 4427.921 GB/s
[2026-03-25|01:11:00] INFO BS= 8192 | Torch Impl: 0.026 ms | 2554.916 GB/s | Old Impl: 0.024 ms | 2819.776 GB/s | New Impl: 0.023 ms | 2944.239 GB/s
[2026-03-25|01:11:00] INFO BS= 16384 | Torch Impl: 0.052 ms | 2572.056 GB/s | Old Impl: 0.045 ms | 3011.029 GB/s | New Impl: 0.045 ms | 3002.043 GB/s
[2026-03-25|01:11:00] INFO BS= 32768 | Torch Impl: 0.103 ms | 2617.506 GB/s | Old Impl: 0.085 ms | 3148.121 GB/s | New Impl: 0.084 ms | 3196.878 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 1 | vocab_range=(32768, 32768), Torch Impl: 0.012 ms | 0.687 GB/s | Old Impl: 0.001 ms | 5.505 GB/s | New Impl: 0.002 ms | 4.881 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 2 | vocab_range=(32768, 32768), Torch Impl: 0.013 ms | 1.268 GB/s | Old Impl: 0.002 ms | 7.149 GB/s | New Impl: 0.002 ms | 7.885 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 4 | vocab_range=(32768, 32768), Torch Impl: 0.013 ms | 2.536 GB/s | Old Impl: 0.001 ms | 22.213 GB/s | New Impl: 0.001 ms | 21.908 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 8 | vocab_range=(32768, 32768), Torch Impl: 0.014 ms | 4.625 GB/s | Old Impl: 0.002 ms | 28.295 GB/s | New Impl: 0.002 ms | 31.668 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 16 | vocab_range=(32768, 32768), Torch Impl: 0.018 ms | 7.348 GB/s | Old Impl: 0.002 ms | 62.755 GB/s | New Impl: 0.002 ms | 57.391 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 32 | vocab_range=(32768, 32768), Torch Impl: 0.012 ms | 21.658 GB/s | Old Impl: 0.002 ms | 115.283 GB/s | New Impl: 0.002 ms | 115.315 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 64 | vocab_range=(32768, 32768), Torch Impl: 0.012 ms | 42.810 GB/s | Old Impl: 0.002 ms | 228.699 GB/s | New Impl: 0.002 ms | 230.663 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 128 | vocab_range=(32768, 32768), Torch Impl: 0.013 ms | 83.660 GB/s | Old Impl: 0.002 ms | 461.261 GB/s | New Impl: 0.002 ms | 457.143 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 256 | vocab_range=(32768, 32768), Torch Impl: 0.014 ms | 145.042 GB/s | Old Impl: 0.002 ms | 846.172 GB/s | New Impl: 0.002 ms | 898.246 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 512 | vocab_range=(32768, 32768), Torch Impl: 0.017 ms | 249.129 GB/s | Old Impl: 0.003 ms | 1563.359 GB/s | New Impl: 0.002 ms | 1679.119 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 1024 | vocab_range=(32768, 32768), Torch Impl: 0.020 ms | 414.969 GB/s | Old Impl: 0.003 ms | 2712.022 GB/s | New Impl: 0.003 ms | 2712.022 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 2048 | vocab_range=(32768, 32768), Torch Impl: 0.029 ms | 584.106 GB/s | Old Impl: 0.004 ms | 3939.942 GB/s | New Impl: 0.004 ms | 3882.464 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 4096 | vocab_range=(32768, 32768), Torch Impl: 0.045 ms | 739.522 GB/s | Old Impl: 0.007 ms | 5135.799 GB/s | New Impl: 0.007 ms | 5103.304 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 8192 | vocab_range=(32768, 32768), Torch Impl: 0.082 ms | 814.517 GB/s | Old Impl: 0.013 ms | 5277.979 GB/s | New Impl: 0.013 ms | 5294.100 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 16384 | vocab_range=(32768, 32768), Torch Impl: 0.157 ms | 857.065 GB/s | Old Impl: 0.030 ms | 4429.605 GB/s | New Impl: 0.030 ms | 4413.199 GB/s
[2026-03-25|01:11:01] INFO [masked] BS= 32768 | vocab_range=(32768, 32768), Torch Impl: 0.306 ms | 876.876 GB/s | Old Impl: 0.056 ms | 4809.954 GB/s | New Impl: 0.056 ms | 4809.954 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 1 | Torch Impl: 0.003 ms | 2.649 GB/s | Old Impl: 0.002 ms | 3.921 GB/s | New Impl: 0.002 ms | 4.903 GB/s | cuTile Impl: 0.001 ms | 5.545 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 2 | Torch Impl: 0.003 ms | 4.908 GB/s | Old Impl: 0.002 ms | 7.145 GB/s | New Impl: 0.001 ms | 11.058 GB/s | cuTile Impl: 0.002 ms | 9.738 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 4 | Torch Impl: 0.004 ms | 7.923 GB/s | Old Impl: 0.002 ms | 15.681 GB/s | New Impl: 0.002 ms | 19.639 GB/s | cuTile Impl: 0.002 ms | 17.585 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 8 | Torch Impl: 0.006 ms | 11.808 GB/s | Old Impl: 0.002 ms | 31.363 GB/s | New Impl: 0.002 ms | 34.973 GB/s | cuTile Impl: 0.002 ms | 34.806 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 16 | Torch Impl: 0.008 ms | 15.533 GB/s | Old Impl: 0.002 ms | 57.658 GB/s | New Impl: 0.002 ms | 70.318 GB/s | cuTile Impl: 0.002 ms | 69.945 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 32 | Torch Impl: 0.003 ms | 90.780 GB/s | Old Impl: 0.002 ms | 115.283 GB/s | New Impl: 0.002 ms | 140.659 GB/s | cuTile Impl: 0.002 ms | 140.635 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 64 | Torch Impl: 0.003 ms | 169.484 GB/s | Old Impl: 0.002 ms | 251.173 GB/s | New Impl: 0.002 ms | 278.450 GB/s | cuTile Impl: 0.002 ms | 278.355 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 128 | Torch Impl: 0.003 ms | 360.722 GB/s | Old Impl: 0.002 ms | 461.261 GB/s | New Impl: 0.002 ms | 502.654 GB/s | cuTile Impl: 0.002 ms | 556.522 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 256 | Torch Impl: 0.003 ms | 673.753 GB/s | Old Impl: 0.002 ms | 846.390 GB/s | New Impl: 0.002 ms | 1003.922 GB/s | cuTile Impl: 0.002 ms | 1003.922 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 512 | Torch Impl: 0.004 ms | 1190.698 GB/s | Old Impl: 0.003 ms | 1651.613 GB/s | New Impl: 0.002 ms | 1680.626 GB/s | cuTile Impl: 0.002 ms | 1692.999 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 1024 | Torch Impl: 0.005 ms | 1853.394 GB/s | Old Impl: 0.003 ms | 2694.737 GB/s | New Impl: 0.003 ms | 2545.087 GB/s | cuTile Impl: 0.003 ms | 2694.183 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 2048 | Torch Impl: 0.006 ms | 2712.723 GB/s | Old Impl: 0.004 ms | 3877.296 GB/s | New Impl: 0.005 ms | 3689.311 GB/s | cuTile Impl: 0.005 ms | 3690.350 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 4096 | Torch Impl: 0.010 ms | 3283.161 GB/s | Old Impl: 0.008 ms | 4190.616 GB/s | New Impl: 0.008 ms | 4416.545 GB/s | cuTile Impl: 0.007 ms | 4551.111 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 8192 | Torch Impl: 0.026 ms | 2539.202 GB/s | Old Impl: 0.024 ms | 2840.784 GB/s | New Impl: 0.023 ms | 2911.417 GB/s | cuTile Impl: 0.023 ms | 2920.377 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 16384 | Torch Impl: 0.052 ms | 2570.559 GB/s | Old Impl: 0.045 ms | 3002.000 GB/s | New Impl: 0.044 ms | 3057.474 GB/s | cuTile Impl: 0.044 ms | 3043.916 GB/s
[2026-03-25|01:11:01] INFO [blackwell] BS= 32768 | Torch Impl: 0.102 ms | 2619.827 GB/s | Old Impl: 0.085 ms | 3145.854 GB/s | New Impl: 0.084 ms | 3185.201 GB/s | cuTile Impl: 0.083 ms | 3223.660 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 1 | vocab_range=(32768, 32768), Torch Impl: 0.010 ms | 0.783 GB/s | Old Impl: 0.001 ms | 5.499 GB/s | New Impl: 0.001 ms | 5.551 GB/s | cuTile Impl: 0.002 ms | 5.453 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 2 | vocab_range=(32768, 32768), Torch Impl: 0.012 ms | 1.375 GB/s | Old Impl: 0.002 ms | 7.852 GB/s | New Impl: 0.002 ms | 7.171 GB/s | cuTile Impl: 0.001 ms | 11.044 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 4 | vocab_range=(32768, 32768), Torch Impl: 0.012 ms | 2.846 GB/s | Old Impl: 0.001 ms | 22.324 GB/s | New Impl: 0.001 ms | 22.217 GB/s | cuTile Impl: 0.002 ms | 19.704 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 8 | vocab_range=(32768, 32768), Torch Impl: 0.014 ms | 4.700 GB/s | Old Impl: 0.002 ms | 31.368 GB/s | New Impl: 0.002 ms | 31.411 GB/s | cuTile Impl: 0.002 ms | 39.506 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 16 | vocab_range=(32768, 32768), Torch Impl: 0.016 ms | 7.990 GB/s | Old Impl: 0.002 ms | 62.601 GB/s | New Impl: 0.002 ms | 62.735 GB/s | cuTile Impl: 0.002 ms | 77.576 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 32 | vocab_range=(32768, 32768), Torch Impl: 0.012 ms | 22.378 GB/s | Old Impl: 0.002 ms | 114.238 GB/s | New Impl: 0.002 ms | 114.830 GB/s | cuTile Impl: 0.002 ms | 155.093 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 64 | vocab_range=(32768, 32768), Torch Impl: 0.012 ms | 43.106 GB/s | Old Impl: 0.002 ms | 250.980 GB/s | New Impl: 0.002 ms | 228.444 GB/s | cuTile Impl: 0.002 ms | 279.829 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 128 | vocab_range=(32768, 32768), Torch Impl: 0.012 ms | 86.489 GB/s | Old Impl: 0.003 ms | 417.267 GB/s | New Impl: 0.002 ms | 457.079 GB/s | cuTile Impl: 0.002 ms | 463.939 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 256 | vocab_range=(32768, 32768), Torch Impl: 0.014 ms | 154.942 GB/s | Old Impl: 0.002 ms | 843.449 GB/s | New Impl: 0.002 ms | 846.281 GB/s | cuTile Impl: 0.002 ms | 1003.922 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 512 | vocab_range=(32768, 32768), Torch Impl: 0.016 ms | 257.009 GB/s | Old Impl: 0.003 ms | 1551.515 GB/s | New Impl: 0.003 ms | 1563.918 GB/s | cuTile Impl: 0.002 ms | 1694.750 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 1024 | vocab_range=(32768, 32768), Torch Impl: 0.020 ms | 424.442 GB/s | Old Impl: 0.003 ms | 2537.942 GB/s | New Impl: 0.003 ms | 2692.799 GB/s | cuTile Impl: 0.003 ms | 2712.864 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 2048 | vocab_range=(32768, 32768), Torch Impl: 0.029 ms | 586.196 GB/s | Old Impl: 0.004 ms | 4075.939 GB/s | New Impl: 0.004 ms | 3882.464 GB/s | cuTile Impl: 0.004 ms | 4035.468 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 4096 | vocab_range=(32768, 32768), Torch Impl: 0.045 ms | 742.192 GB/s | Old Impl: 0.007 ms | 5103.801 GB/s | New Impl: 0.006 ms | 5268.167 GB/s | cuTile Impl: 0.006 ms | 5218.094 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 8192 | vocab_range=(32768, 32768), Torch Impl: 0.083 ms | 812.497 GB/s | Old Impl: 0.013 ms | 5242.880 GB/s | New Impl: 0.013 ms | 5234.897 GB/s | cuTile Impl: 0.012 ms | 5601.368 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 16384 | vocab_range=(32768, 32768), Torch Impl: 0.156 ms | 858.702 GB/s | Old Impl: 0.030 ms | 4474.927 GB/s | New Impl: 0.030 ms | 4462.785 GB/s | cuTile Impl: 0.031 ms | 4385.008 GB/s
[2026-03-25|01:11:02] INFO [blackwell-masked] BS= 32768 | vocab_range=(32768, 32768), Torch Impl: 0.306 ms | 876.412 GB/s | Old Impl: 0.056 ms | 4781.932 GB/s | New Impl: 0.056 ms | 4779.316 GB/s | cuTile Impl: 0.058 ms | 4612.800 GB/s
For the unmasked case, CuTile > CuTe-DSL > CUDA; for the masked case, CuTe-DSL > CUDA > CuTile, though the improvements are marginal. The unmasked problem is a very regular 2D gather/scatter over (row_tile, col_tile), whereas the CuTe-DSL and CUDA versions express the problem in terms of warps, which incurs slightly more overhead. For the masked case, CuTile now has to do extra row math, build a validity mask, materialize a where, and run the tile gather/scatter path with bounds checks. Meanwhile, the CuTe-DSL and CUDA versions decide validity once per row/split, then either copy or zero-fill directly.
Onto the fused MoE matmul and reduce!
fused_moe_kernel_triton / moe_sum_reduce_triton
We're going to do something slightly different in this section. Instead of trying to match perf with a CuTe/CuTile version (i.e., I tried and failed), we'll just explore the Triton version instead.
mini-sglang
# llmeng/kernel_new/fused_moe.py
@triton.jit
def moe_sum_reduce_kernel(
input_ptr,
input_stride_0,
input_stride_1,
input_stride_2,
output_ptr,
output_stride_0,
output_stride_1,
token_num: int,
topk_num: int,
hidden_dim: int,
BLOCK_M: tl.constexpr,
BLOCK_DIM: tl.constexpr,
NUM_STAGE: tl.constexpr,
):
input_stride_0 = tl.cast(input_stride_0, dtype=tl.int64)
input_stride_1 = tl.cast(input_stride_1, dtype=tl.int64)
output_stride_0 = tl.cast(output_stride_0, dtype=tl.int64)
token_block_id = tl.program_id(0)
dim_block_id = tl.program_id(1)
token_start = token_block_id * BLOCK_M
token_end = min((token_block_id + 1) * BLOCK_M, token_num)
dim_start = dim_block_id * BLOCK_DIM
dim_end = min((dim_block_id + 1) * BLOCK_DIM, hidden_dim)
offs_dim = dim_start + tl.arange(0, BLOCK_DIM)
for token_index in range(token_start, token_end):
accumulator = tl.zeros((BLOCK_DIM,), dtype=tl.float32)
input_t_ptr = input_ptr + token_index * input_stride_0 + offs_dim
for i in tl.range(0, topk_num, num_stages=NUM_STAGE):
tmp = tl.load(
input_t_ptr + i * input_stride_1, mask=offs_dim < dim_end, other=0.0
)
accumulator += tmp
store_t_ptr = output_ptr + token_index * output_stride_0 + offs_dim
tl.store(
store_t_ptr,
accumulator.to(input_ptr.dtype.element_ty),
mask=offs_dim < dim_end,
)
@triton.jit
def fused_moe_kernel(
# Pointers to matrices
a_ptr,
b_ptr,
c_ptr,
topk_weights_ptr,
sorted_token_ids_ptr,
expert_ids_ptr,
num_tokens_post_padded_ptr,
# Matrix dimensions
N,
K,
EM,
num_valid_tokens,
# The stride variables represent how much to increase the ptr by when
# moving by 1 element in a particular dimension. E.g. `stride_am` is
# how much to increase `a_ptr` by to get the element one row down
# (A has M rows).
stride_am,
stride_ak,
stride_be,
stride_bk,
stride_bn,
stride_cm,
stride_cn,
# Meta-parameters
BLOCK_SIZE_M: tl.constexpr,
BLOCK_SIZE_N: tl.constexpr,
BLOCK_SIZE_K: tl.constexpr,
GROUP_SIZE_M: tl.constexpr,
MUL_ROUTED_WEIGHT: tl.constexpr,
top_k: tl.constexpr,
compute_type: tl.constexpr,
even_Ks: tl.constexpr,
):
"""
Implements the fused computation for a Mixture of Experts (MOE) using
token and expert matrices.
Key Parameters:
- A: The input tensor representing tokens with shape (*, K), where '*' can
be any shape representing batches and K is the feature dimension of
each token.
- B: The stacked MOE weight tensor with shape (E, N, K), where E is
the number of experts, K is the input feature dimension, and N is
the output feature dimension.
- C: The output cache tensor with shape (M, topk, N), where M is the
total number of tokens post padding, topk is the number of times
each token is repeated, and N is the output feature dimension.
- sorted_token_ids: A tensor containing the sorted indices of tokens,
repeated topk times and arranged by the expert index they are
assigned to.
- expert_ids: A tensor containing the indices of the expert for each
block. It determines which expert matrix from B should be used for
each block in A.
This kernel performs the multiplication of a token by its corresponding
expert matrix as determined by `expert_ids`. The sorting of
`sorted_token_ids` by expert index and padding ensures divisibility by
BLOCK_SIZE_M, which is necessary to maintain consistency in block matrix
multiplication across different blocks processed by the same expert.
"""
# -----------------------------------------------------------
# Map program ids `pid` to the block of C it should compute.
# This is done in a grouped ordering to promote L2 data reuse.
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(EM, BLOCK_SIZE_M)
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + ((pid % num_pid_in_group) % group_size_m)
pid_n = (pid % num_pid_in_group) // group_size_m
# ----------------------------------------------------------
# Create pointers for the first blocks of A and B.
# We will advance this pointer as we move in the K direction
# and accumulate
# `a_ptrs` is a block of [BLOCK_SIZE_M, BLOCK_SIZE_K] pointers
# `b_ptrs` is a block of [BLOCK_SIZE_K, BLOCK_SIZE_N] pointers
num_tokens_post_padded = tl.load(num_tokens_post_padded_ptr)
if pid_m * BLOCK_SIZE_M >= num_tokens_post_padded:
return
offs_token_id = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_token = tl.load(sorted_token_ids_ptr + offs_token_id)
offs_token = offs_token.to(tl.int64)
token_mask = offs_token < num_valid_tokens
offs_bn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N
offs_k = tl.arange(0, BLOCK_SIZE_K)
a_ptrs = a_ptr + (
offs_token[:, None] // top_k * stride_am + offs_k[None, :] * stride_ak
)
off_experts = tl.load(expert_ids_ptr + pid_m)
b_ptrs = (
b_ptr
+ off_experts * stride_be
+ (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn)
)
# -----------------------------------------------------------
# Iterate to compute a block of the C matrix.
# We accumulate into a `[BLOCK_SIZE_M, BLOCK_SIZE_N]` block
# of fp32 values for higher accuracy.
# `accumulator` will be converted back to fp16 after the loop.
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)):
# Load the next block of A and B, generate a mask by checking the
# K dimension.
if even_Ks:
a = tl.load(
a_ptrs,
mask=token_mask[:, None],
other=0.0,
)
b = tl.load(b_ptrs)
else:
a = tl.load(
a_ptrs,
mask=token_mask[:, None] & (offs_k[None, :] < K - k * BLOCK_SIZE_K),
other=0.0,
)
b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k * BLOCK_SIZE_K, other=0.0)
# We accumulate along the K dimension.
accumulator += tl.dot(a, b)
# Advance the ptrs to the next K block.
a_ptrs += BLOCK_SIZE_K * stride_ak
b_ptrs += BLOCK_SIZE_K * stride_bk
if MUL_ROUTED_WEIGHT:
moe_weight = tl.load(topk_weights_ptr + offs_token, mask=token_mask, other=0)
accumulator = accumulator * moe_weight[:, None]
accumulator = accumulator.to(compute_type)
# -----------------------------------------------------------
# Write back the block of the output
offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
c_ptrs = c_ptr + stride_cm * offs_token[:, None] + stride_cn * offs_cn[None, :]
c_mask = token_mask[:, None] & (offs_cn[None, :] < N)
tl.store(c_ptrs, accumulator, mask=c_mask)
def fused_moe_kernel_triton(
A: torch.Tensor,
B: torch.Tensor,
C: torch.Tensor,
topk_weights: torch.Tensor,
topk_ids: torch.Tensor,
sorted_token_ids: torch.Tensor,
expert_ids: torch.Tensor,
num_tokens_post_padded: torch.Tensor,
mul_routed_weight: bool,
top_k: int,
config: Dict[str, Any],
compute_type: torch.dtype,
) -> None:
assert topk_weights.stride(1) == 1
assert sorted_token_ids.stride(0) == 1
padded_size = 0
def grid(META):
return (
triton.cdiv(sorted_token_ids.shape[0], META["BLOCK_SIZE_M"])
* triton.cdiv(B.shape[1], META["BLOCK_SIZE_N"]),
)
K = B.shape[2] - padded_size
if K % config["BLOCK_SIZE_K"] == 0:
even_Ks = True
else:
even_Ks = False
dtype = tl.bfloat16 if compute_type == torch.bfloat16 else tl.float16
fused_moe_kernel[grid](
A,
B,
C,
topk_weights,
sorted_token_ids,
expert_ids,
num_tokens_post_padded,
B.shape[1],
B.shape[2] - padded_size,
sorted_token_ids.shape[0],
topk_ids.numel(),
A.stride(0),
A.stride(1),
B.stride(0),
B.stride(2),
B.stride(1),
C.stride(1),
C.stride(2),
MUL_ROUTED_WEIGHT=mul_routed_weight, # type: ignore
top_k=top_k, # type: ignore
compute_type=dtype, # type: ignore
even_Ks=even_Ks, # type: ignore
**config,
)
def moe_sum_reduce_triton(input: torch.Tensor, output: torch.Tensor) -> None:
assert input.is_contiguous()
assert output.is_contiguous()
token_num, topk_num, hidden_dim = input.shape
assert output.shape[0] == token_num and output.shape[1] == hidden_dim
BLOCK_M = 1
BLOCK_DIM = 2048
NUM_STAGE = 1
num_warps = 8
grid = (
triton.cdiv(token_num, BLOCK_M),
triton.cdiv(hidden_dim, BLOCK_DIM),
)
moe_sum_reduce_kernel[grid](
input,
*input.stride(),
output, # type: ignore
*output.stride(),
token_num=token_num,
topk_num=topk_num,
hidden_dim=hidden_dim,
BLOCK_M=BLOCK_M,
BLOCK_DIM=BLOCK_DIM,
NUM_STAGE=NUM_STAGE,
num_warps=num_warps, # type: ignore
)
The core idea is that by sorting token replicas by expert and padding to BLOCK_SIZE_M, we turn the irregular routing structure into a regular block-structured op. Afterwards, it's a standard tiled matmul over K, making the first kernel mostly compute-bound. The reduction kernel, on the other hand, is mostly memory-bound. By fixing BLOCK_M = 1 and BLOCK_DIM = 2048, it processes one token row at a time.
Running modal run ci.py --target tests/kernel/test_moe.py we get:
[2026-03-25|21:00:01] INFO fused_moe | M= 512 | E= 32 | H=1024 | I= 4096 | topk=8 | Torch Impl: 4.535 ms | 202.093 GB/s | Old Impl: 2.472 ms | 370.693 GB/s
[2026-03-25|21:00:01] INFO moe_sum_reduce | M= 4096 | topk=8 | H=2048 | Torch Impl: 0.043 ms | 3487.245 GB/s | Old Impl: 0.031 ms | 4816.364 GB/s
About 1.83x faster than Torch for the matmuls and 1.38x faster for the reduce.
Lastly, everything NCCL related.
init_pynccl / PyNCCLCommunicator
mini-sglang
# llmeng/kernel_old/pynccl.py
class PyNCCLCommunicator:
@abstractmethod
def all_reduce(self, input: torch.Tensor, op: Literal["sum"]) -> None: ...
@abstractmethod
def all_gather(self, output: torch.Tensor, input: torch.Tensor) -> None: ...
@abstractmethod
def get_buffer(self) -> int: ...
@functools.cache
def _load_nccl_module() -> Module:
return load_aot("pynccl", cuda_files=["pynccl.cu"], extra_ldflags=["-lnccl"])
@functools.cache
def _get_pynccl_wrapper_cls():
import tvm_ffi
@tvm_ffi.register_object("minisgl.NCCLWrapper")
class PyNCCLImpl(tvm_ffi.Object):
def __init__(self, *args):
self.__ffi_init__(*args)
return PyNCCLImpl
def init_pynccl(
*,
tp_rank: int,
tp_size: int,
tp_cpu_group: torch.distributed.ProcessGroup,
max_size_bytes: int = 0,
) -> PyNCCLCommunicator:
import torch
max_size_bytes = min(max_size_bytes, ENV.PYNCCL_MAX_BUFFER_SIZE.value)
module = _load_nccl_module()
cls = _get_pynccl_wrapper_cls()
if tp_rank == 0:
id_list = [module.create_nccl_uid()]
torch.distributed.broadcast_object_list(
id_list,
src=0,
group=tp_cpu_group,
)
else:
id_list = [None]
torch.distributed.broadcast_object_list(
id_list,
src=0,
group=tp_cpu_group,
)
nccl_id = id_list[0]
assert nccl_id is not None, f"Failed to get NCCL unique ID on {tp_rank = }"
# bypass type checking for the FFI object
return cls(tp_rank, tp_size, max_size_bytes, nccl_id) # type: ignore
// llmeng/kernel_old/csrc/src/pynccl.cu
struct NCCLWrapper : public tvm::ffi::Object {
public:
NCCLWrapper(int rank, int world_size, const size_t max_bytes, NCCLIDList uid)
: m_rank(rank), m_world_size(world_size), m_max_bytes(max_bytes) {
ncclUniqueId id = get_uid(uid);
ncclComm_t comm;
NCCL_CHECK(::ncclCommInitRank(&comm, m_world_size, id, m_rank));
m_comm = {comm, template_fn<::ncclCommDestroy>};
void *buf;
NCCL_CHECK(::ncclMemAlloc(&buf, max_bytes));
m_sym_mem = {buf, template_fn<::ncclMemFree>};
ncclWindow_t win;
NCCL_CHECK(::ncclCommWindowRegister(comm, buf, max_bytes, &win,
NCCL_WIN_COLL_SYMMETRIC));
m_win = {win, [comm = m_comm](ncclWindow_t w) {
return NCCL_CHECK(::ncclCommWindowDeregister(comm.get(), w));
}};
}
auto all_reduce(tvm::ffi::TensorView t, std::string op) const -> void {
using namespace host;
RuntimeCheck(t.device().device_type == kDLCUDA,
"Tensor must be on CUDA device");
RuntimeCheck(t.is_contiguous(), "Tensor must be contiguous");
const auto size_dim = static_cast<size_t>(t.shape().Product());
const auto dtype = kNCCLDtypeMap.at(t.dtype());
const auto size_bytes = size_dim * (t.dtype().bits / 8);
const auto data_ptr = t.data_ptr();
const auto reduce_op = kNCCLReduceOPMap.at(op);
const auto stream = LaunchKernel::resolve_device(t.device());
if (size_bytes <= m_max_bytes) { // use internal buffer
const auto buf_ptr = m_sym_mem.get();
const auto need_memcpy = (buf_ptr != data_ptr);
if (need_memcpy) {
CUDA_CHECK(::cudaMemcpyAsync(buf_ptr, data_ptr, size_bytes,
::cudaMemcpyDeviceToDevice, stream));
}
NCCL_CHECK(::ncclAllReduce(
/*sendbuff=*/buf_ptr,
/*recvbuff=*/buf_ptr,
/*count=*/size_dim,
/*datatype=*/dtype,
/*op=*/reduce_op,
/*comm=*/m_comm.get(),
/*stream=*/stream));
if (need_memcpy) {
CUDA_CHECK(::cudaMemcpyAsync(data_ptr, buf_ptr, size_bytes,
::cudaMemcpyDeviceToDevice, stream));
}
} else {
NCCL_CHECK(::ncclAllReduce(
/*sendbuff=*/data_ptr,
/*recvbuff=*/data_ptr,
/*count=*/size_dim,
/*datatype=*/dtype,
/*op=*/reduce_op,
/*comm=*/m_comm.get(),
/*stream=*/stream));
}
}
auto all_gather(tvm::ffi::TensorView dst, tvm::ffi::TensorView src) const
-> void {
using namespace host;
RuntimeCheck(src.device().device_type == kDLCUDA,
"Tensor must be on CUDA device");
RuntimeCheck(src.is_contiguous(), "Tensor must be contiguous");
RuntimeCheck(dst.device().device_type == kDLCUDA,
"Tensor must be on CUDA device");
RuntimeCheck(dst.is_contiguous(), "Tensor must be contiguous");
RuntimeCheck(dst.size(0) == src.size(0) * m_world_size,
"Destination tensor has incorrect size");
const auto size_dim = static_cast<size_t>(src.shape().Product());
const auto dtype = kNCCLDtypeMap.at(src.dtype());
const auto src_ptr = src.data_ptr();
const auto dst_ptr = dst.data_ptr();
const auto stream = LaunchKernel::resolve_device(src.device());
// do not use internal buffer for all_gather, directly gather to output
// tensor
NCCL_CHECK(::ncclAllGather(
/*sendbuff=*/src_ptr,
/*recvbuff=*/dst_ptr,
/*sendcount=*/size_dim,
/*datatype=*/dtype,
/*comm=*/m_comm.get(),
/*stream=*/stream));
}
auto get_buffer() const -> void * { return m_sym_mem.get(); }
TVM_FFI_DECLARE_OBJECT_INFO_FINAL("minisgl.NCCLWrapper", NCCLWrapper,
tvm::ffi::Object);
private:
int m_rank;
int m_world_size;
size_t m_max_bytes;
shared_obj<ncclComm_t> m_comm;
shared_ptr<void> m_sym_mem;
shared_obj<ncclWindow_t> m_win;
};
TVM_FFI_STATIC_INIT_BLOCK() {
namespace refl = tvm::ffi::reflection;
refl::ObjectDef<NCCLWrapper>()
.def(refl::init<int, int, size_t, NCCLIDList>(), "__init__")
.def("all_reduce", &NCCLWrapper::all_reduce)
.def("all_gather", &NCCLWrapper::all_gather)
.def("get_buffer", &NCCLWrapper::get_buffer);
}
TVM_FFI_DLL_EXPORT_TYPED_FUNC(create_nccl_uid, &create_uid);
We see that a unique NCCL id is broadcasted across the TP CPU group in Python. Then, in CUDA, we initialize the communicator and optionally allocate a symmetric scratch buffer and register it as an NCCL window for lower latency.
llm-engine
# llmeng/kernel_new/nccl.py
ReduceOp = Literal["sum", "prod", "max", "min", "avg"]
def _required_bytes(tensor: torch.Tensor) -> int:
return tensor.numel() * tensor.element_size()
def _resolve_output_shape(tensor: torch.Tensor, world_size: int) -> tuple[int, ...]:
if tensor.ndim == 0:
raise RuntimeError("reduce_scatter requires at least 1D input")
if tensor.shape[0] % world_size != 0:
raise RuntimeError(
"reduce_scatter requires the leading dimension to be divisible by world size"
)
return (tensor.shape[0] // world_size, *tensor.shape[1:])
def _resolve_gather_shape(tensor: torch.Tensor, world_size: int) -> tuple[int, ...]:
if tensor.ndim == 0:
raise RuntimeError("all_gather requires at least 1D input")
return (tensor.shape[0] * world_size, *tensor.shape[1:])
class NcclCommunicator:
def __init__(
self,
*,
communicator: Any,
world_size: int,
rank: int,
device: torch.device,
scratch_tensor: torch.Tensor | None,
scratch_handle: Any | None,
scratch_window: Any | None,
max_size_bytes: int,
) -> None:
self._comm = communicator
self.world_size = world_size
self.rank = rank
self.device = device
self.max_size_bytes = max_size_bytes
self._scratch_tensor = scratch_tensor
self._scratch_handle = scratch_handle
self._scratch_window = scratch_window
self._destroyed = False
def _check_active(self) -> None:
if self._destroyed:
raise RuntimeError("NcclCommunicator has been destroyed")
def _check_cuda_tensor(self, name: str, tensor: torch.Tensor) -> None:
if tensor.device != self.device:
raise RuntimeError(
f"{name} must be on communicator device {self.device}, got {tensor.device}"
)
if tensor.device.type != "cuda":
raise RuntimeError(f"{name} must be a CUDA tensor")
if not tensor.is_contiguous():
raise RuntimeError(f"{name} must be contiguous")
def _stream_ptr(self, tensor: torch.Tensor) -> int:
import torch
return int(torch.cuda.current_stream(device=tensor.device).cuda_stream)
def _close_resource(self, resource: Any) -> None:
try:
resource.close()
except Exception:
pass
def _scratch_view_like(self, tensor: torch.Tensor) -> torch.Tensor | None:
if self._scratch_tensor is None:
return None
size_bytes = _required_bytes(tensor)
if size_bytes == 0 or size_bytes > self.max_size_bytes:
return None
return self._scratch_tensor[:size_bytes].view(tensor.dtype).view_as(tensor)
def all_reduce(self, input: torch.Tensor, op: ReduceOp = "sum") -> None:
import nccl.bindings as nccl_bindings
import nccl.core as nccl
from nccl.core.interop.torch import resolve_tensor
self._check_active()
self._check_cuda_tensor("input", input)
if input.numel() == 0:
return
target = input
scratch = self._scratch_view_like(input)
if scratch is not None:
target = scratch
if target.data_ptr() != input.data_ptr():
target.copy_(input, non_blocking=True)
reduce_op = {
"sum": int(nccl.SUM),
"prod": int(nccl.PROD),
"max": int(nccl.MAX),
"min": int(nccl.MIN),
"avg": int(nccl.AVG),
}[op]
ptr, count, dtype, _ = resolve_tensor(target)
nccl_bindings.all_reduce(
ptr,
ptr,
count,
int(dtype),
reduce_op,
self._comm.ptr,
self._stream_ptr(input),
)
if target.data_ptr() != input.data_ptr():
input.copy_(target, non_blocking=True)
def all_gather(self, output: torch.Tensor, input: torch.Tensor) -> None:
import nccl.bindings as nccl_bindings
from nccl.core.interop.torch import resolve_tensor
self._check_active()
self._check_cuda_tensor("input", input)
self._check_cuda_tensor("output", output)
if input.numel() == 0:
return
if output.dtype != input.dtype:
raise RuntimeError("all_gather requires matching input/output dtypes")
expected_shape = _resolve_gather_shape(input, self.world_size)
if tuple(output.shape) != expected_shape:
raise RuntimeError(
"all_gather output shape must match the gathered leading dimension"
)
src_ptr, count, dtype, _ = resolve_tensor(input)
dst_ptr, _, _, _ = resolve_tensor(output)
nccl_bindings.all_gather(
src_ptr,
dst_ptr,
count,
int(dtype),
self._comm.ptr,
self._stream_ptr(input),
)
def reduce_scatter(
self,
input: torch.Tensor,
output: torch.Tensor | None = None,
op: ReduceOp = "sum",
) -> torch.Tensor:
import nccl.bindings as nccl_bindings
import nccl.core as nccl
from nccl.core.interop.torch import resolve_tensor
self._check_active()
self._check_cuda_tensor("input", input)
if input.numel() == 0:
if output is None:
return input.new_empty(_resolve_output_shape(input, self.world_size))
self._check_cuda_tensor("output", output)
return output
if input.numel() % self.world_size != 0:
raise RuntimeError(
"reduce_scatter input element count must be divisible by world size"
)
if output is None:
output = input.new_empty(_resolve_output_shape(input, self.world_size))
self._check_cuda_tensor("output", output)
if output.dtype != input.dtype:
raise RuntimeError("reduce_scatter requires matching input/output dtypes")
expected_shape = _resolve_output_shape(input, self.world_size)
if tuple(output.shape) != expected_shape:
raise RuntimeError(
"reduce_scatter output shape must match the scattered leading dimension"
)
reduce_op = {
"sum": int(nccl.SUM),
"prod": int(nccl.PROD),
"max": int(nccl.MAX),
"min": int(nccl.MIN),
"avg": int(nccl.AVG),
}[op]
src_ptr, _, dtype, _ = resolve_tensor(input)
dst_ptr, count, _, _ = resolve_tensor(output)
nccl_bindings.reduce_scatter(
src_ptr,
dst_ptr,
count,
int(dtype),
reduce_op,
self._comm.ptr,
self._stream_ptr(input),
)
return output
def get_buffer(self) -> int:
if self._scratch_tensor is None:
return 0
return int(self._scratch_tensor.data_ptr())
def destroy(self) -> None:
if self._destroyed:
return
self._destroyed = True
for resource in (self._scratch_window, self._scratch_handle):
if resource is None:
continue
self._close_resource(resource)
self._scratch_window = None
self._scratch_handle = None
self._scratch_tensor = None
self._comm.destroy()
close = destroy
def init_nccl(
*,
local_rank: int,
local_size: int,
global_rank: int,
global_size: int,
tp_cpu_group: torch.distributed.ProcessGroup,
max_size_bytes: int = 0,
) -> NcclCommunicator:
import nccl.core as nccl
import torch
import torch.distributed as dist
from nccl.core.interop.torch import empty as nccl_empty
if local_rank < 0:
raise RuntimeError(f"local_rank must be non-negative, got {local_rank}")
if local_size < 1:
raise RuntimeError(f"local_size must be positive, got {local_size}")
if max_size_bytes < 0:
raise RuntimeError(f"max_size_bytes must be non-negative, got {max_size_bytes}")
torch.cuda.set_device(local_rank)
device = torch.device(f"cuda:{local_rank}")
max_size_bytes = min(max_size_bytes, ENV.NCCL_MAX_BUFFER_SIZE.value)
group_rank = dist.get_rank(group=tp_cpu_group)
group_size = dist.get_world_size(group=tp_cpu_group)
if global_rank != group_rank or global_size != group_size:
raise RuntimeError(
"init_nccl requires global_rank/global_size to match tp_cpu_group scope"
)
uid_list = [nccl.get_unique_id().as_bytes if group_rank == 0 else None]
dist.broadcast_object_list(uid_list, src=0, group=tp_cpu_group)
uid_bytes = uid_list[0]
if uid_bytes is None:
raise RuntimeError("Failed to broadcast NCCL unique id")
communicator = nccl.Communicator.init(
nranks=group_size,
rank=group_rank,
unique_id=nccl.UniqueId.from_bytes(uid_bytes),
)
scratch_tensor = None
scratch_handle = None
scratch_window = None
if max_size_bytes > 0:
scratch_tensor = nccl_empty(
(max_size_bytes,),
dtype=torch.uint8,
device=device,
)
scratch_handle = communicator.register_buffer(scratch_tensor)
scratch_window = communicator.register_window(
scratch_tensor, nccl.WindowFlag.CollSymmetric
)
return NcclCommunicator(
communicator=communicator,
world_size=group_size,
rank=group_rank,
device=device,
scratch_tensor=scratch_tensor,
scratch_handle=scratch_handle,
scratch_window=scratch_window,
max_size_bytes=max_size_bytes,
)
Ours does essentially the same thing using the nccl4py package.
Running uv run modal run ci.py --target tests/kernel/test_comm.py we get:
[2026-03-25|09:09:28|core|rank=1] INFO Rank 1 old all-reduce avg time: 40.4694 us
[2026-03-25|09:09:28|core|rank=0] INFO Rank 0 old all-reduce avg time: 40.4691 us
[2026-03-25|09:09:28|core|rank=1] INFO Rank 1 old all-reduce bandwidth: 207.28 GB/s
[2026-03-25|09:09:28|core|rank=0] INFO Rank 0 old all-reduce bandwidth: 207.28 GB/s
[2026-03-25|09:09:28|core|rank=0] INFO Rank 0 old memory usage: 8.00 MB
[2026-03-25|09:09:28|core|rank=1] INFO Rank 1 old memory usage: 8.00 MB
[2026-03-25|09:09:28|core|rank=1] INFO Rank 1 new all-reduce avg time: 40.7553 us
[2026-03-25|09:09:28|core|rank=1] INFO Rank 1 new all-reduce bandwidth: 205.83 GB/s
[2026-03-25|09:09:28|core|rank=1] INFO Rank 1 new memory usage: 8.00 MB
[2026-03-25|09:09:28|core|rank=0] INFO Rank 0 new all-reduce avg time: 40.7556 us
[2026-03-25|09:09:28|core|rank=0] INFO Rank 0 new all-reduce bandwidth: 205.83 GB/s
[2026-03-25|09:09:28|core|rank=0] INFO Rank 0 new memory usage: 8.00 MB
Essentially the same! Not super interesting, but good to show.
Aside: Benchmarking
As a tangent, while we've already confirmed that our kernels above are functionally equivalent but slightly faster, the original repo lacked proper benchmarking (i.e., it wasn't as comprehensive as something like the LLM Almanac). So I just ripped out what I needed from the open source code and had GPT 5.4-High replicate a similar-looking graph in HTML. I then decided to benchmark Qwen3-32B and Qwen3-30B-A3B to test both dense and MoE models.
After running modal run benchmark/main.py --rate-type constant, we get something like:
Also, see the repo for more nifty Modal-specifics for serving the API and benchmarking; you can do some pretty cool stuff.
Thanks for reading!
Footnotes
Shameless plug: see this Street Fighter III project I made as an ML intern on the growth team at Modal!↩